Классификация модемных протоколовСтраница 28
Рис. 5.2. Кодирование при помощи марковского алгоритма прогнозирования и кода Хаффмена
Марковский алгоритм может предсказывать следующий символ в последовательности, исходя из появившегося предыдущего символа. Для каждого октета формируется таблица из всех 256 возможных следующих за ним октетов, расположенных в соответствии с частотой их появления. Октет кодируется путем выбора столбца, соответствующего предыдущему октету (озаглавливающему столбец), с последующим отысканием в этом столбце значения текущего октета. Строка, в которой находится текущий октет, определяет лексему точно так же, как в описанном выше случае кодирования с использованием кода Хаффмена После того как каждый октет будет закодирован, порядок следования записей (октетов) в выбранном столбце изменяется в соответствии с новыми относительными частотами появления октетов.
На рис. 5.2 показан пример кодирования последовательности октетов 3120 в предположении, что перед этим был передан октет 0. Из рис. 5.2. видно, что в столбце, соответствующем предыдущему октету 0, отыскивается запись (строка) октета 3. После этого передается код Хаффмена для этой записи (октета 3) в таблице. Далее в столбце, соответствующем этому только что переданному октету 3, отыскивается строка с записью следующего октета — в данном случае октета 1, и передается код Хаффмена для этой строки и т.д. В этом примере отсутствует иллюстрация адаптивной части алгоритма, изменяющей порядок расположения октетов в каждом столбце.
5.3. Сжатие данных по стандарту V.42bis
В настоящее время методы сжатия данных, включенные в протоколы MNP5 и MNP7, целенаправленно заменяются на метод, основанный на алгоритме словарного типа Лемпеля-Зива-Уэлча (LZW-алгоритме). LZW-алгоритм имеет два главных преимущества:
Ø обеспечивает достижение коэффициента сжатия 4:1 файлов с оптимальной структурой;
Ø LZW-метод утвержден ITU-T как составная часть стандарта V.42bis. .
Метод сжатия данных LZW основан на создании древовидного словаря последовательностей символов, в котором каждой последовательности соответствует единственное кодовое слово. Входящий поток данных последовательно, символ за символом, сравнивается с имеющимися в словаре последовательностями. После того, как в словаре будет найдена кодируемая последовательность, идентичная входной, модем передает соответствующее ей кодовое слово. Алгоритм динамически создает и обновляет словарь символьных последовательностей.
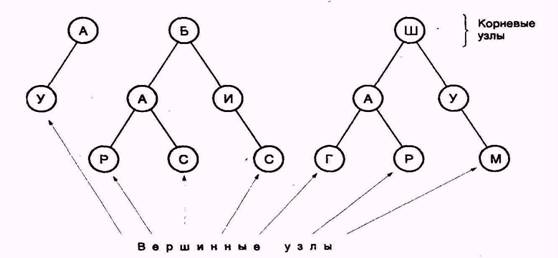 |
Рис. 5.3. Пример структуры древовидного словаря последовательностей стандарта V.42bis
Алгоритм сжатия, определяемый стандартом V.42bis, весьма гибок. К параметрам, значения которых могут быть согласованы между модемами, относятся: максимальный размер кодового слова, общее число кодовых слов, размер символа, число символов в алфавите и максимальная длина последовательности. Кроме того, алгоритм осуществляет мониторинг входного и выходного потока данных для определения эффективности сжатия. Если сжатия не происходит или оно невозможно (в силу природы передаваемых данных) алгоритм прекращает свою работу. Это свойство обеспечивает лучшие рабочие характеристики при передаче файлов, которые уже были сжаты (заархивированы) или которые не поддаются сжатию.